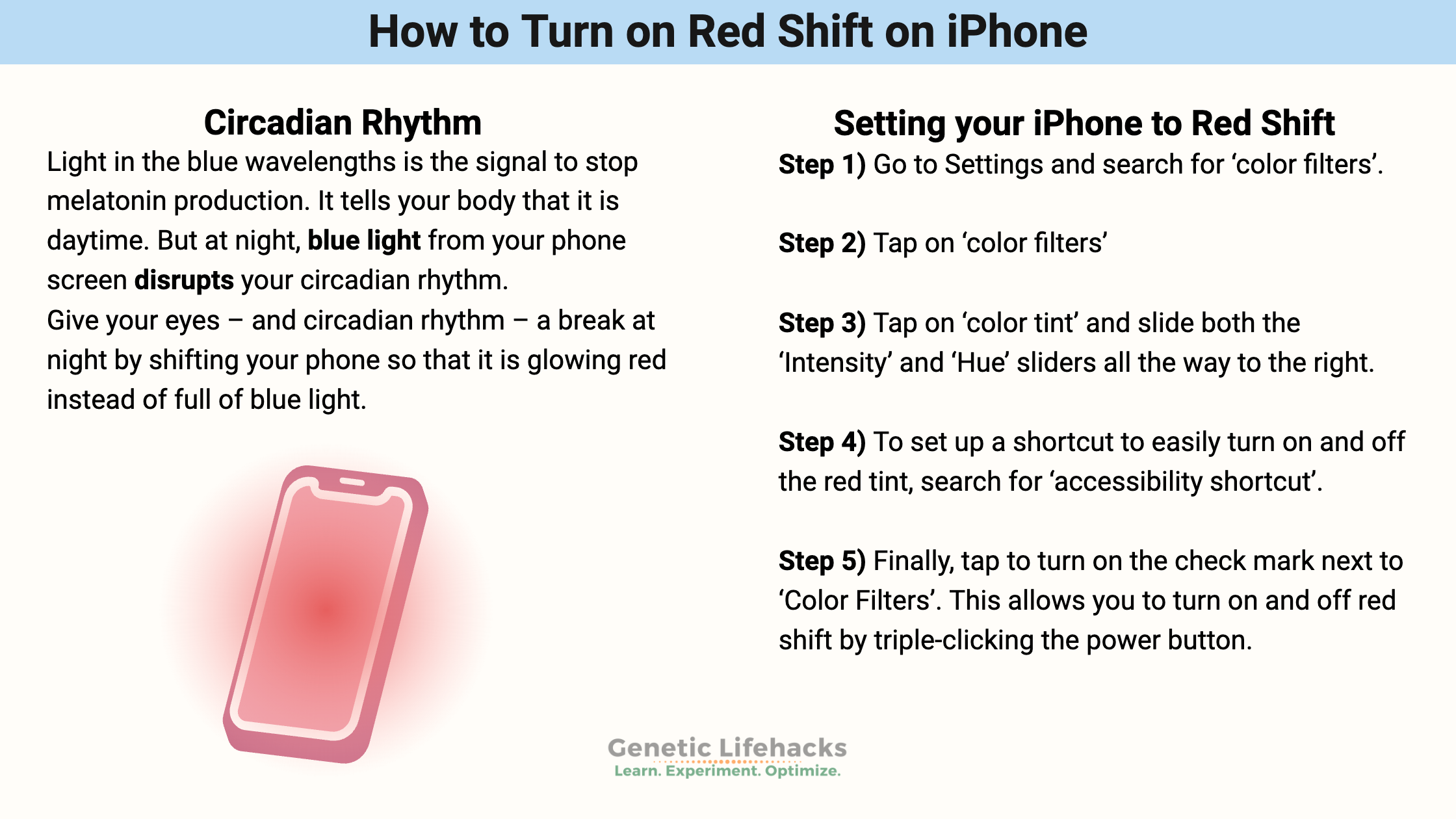
How to Shift Your iPhone Screen to Red at Night
Learn how to shift your iphone screen to be completely red at night (no blue light) with a triple-click of the power button.
Learn how to shift your iphone screen to be completely red at night (no blue light) with a triple-click of the power button.
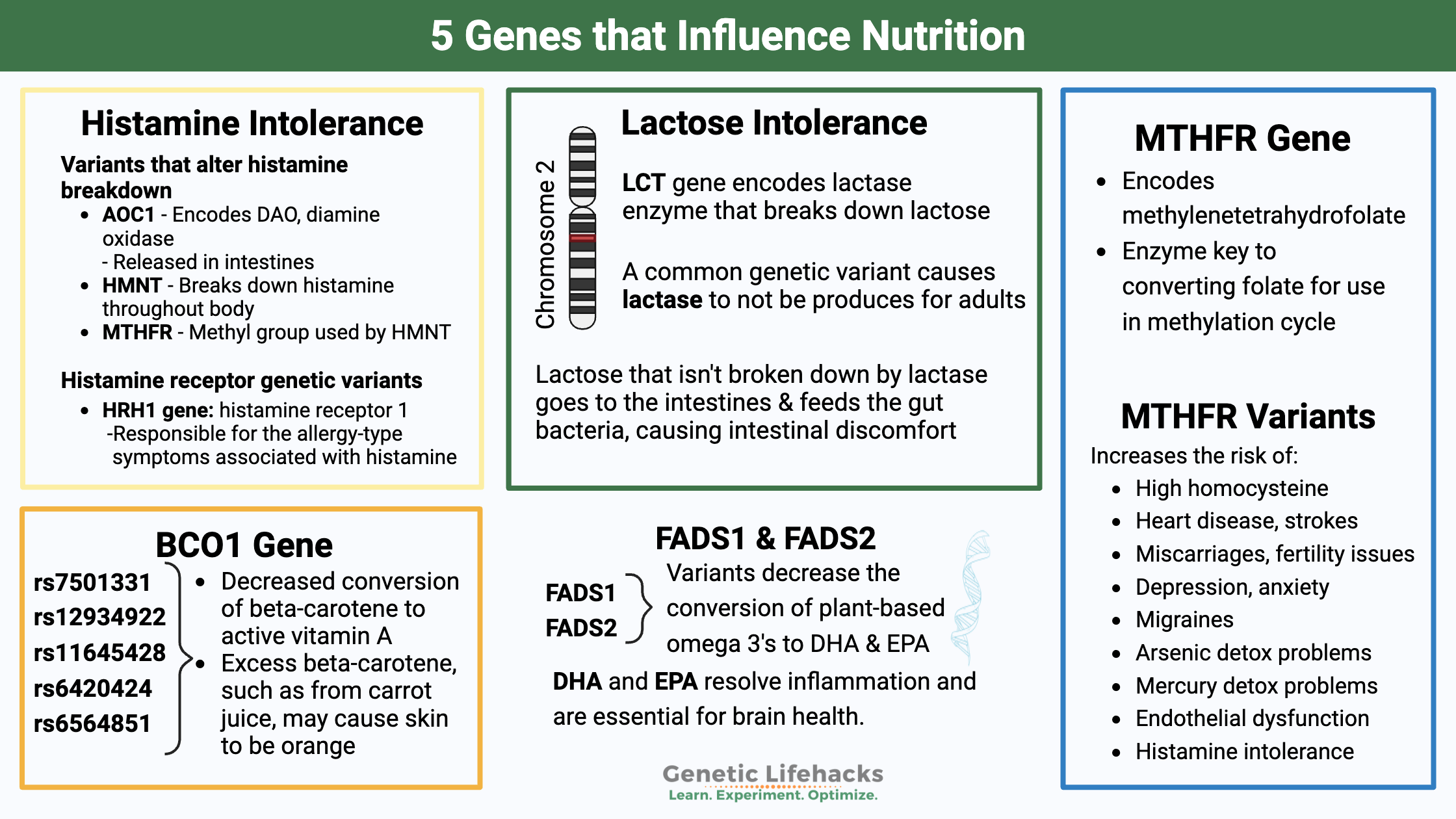
BookmarkTired of guessing which vitamins and nutrients you need more of? Use your genetic raw data from 23andMe or AncestryDNA to find out! Here are five examples of how you can use your genetic data to understand how your genes can influence your need for specific nutrients. This is a … Read more
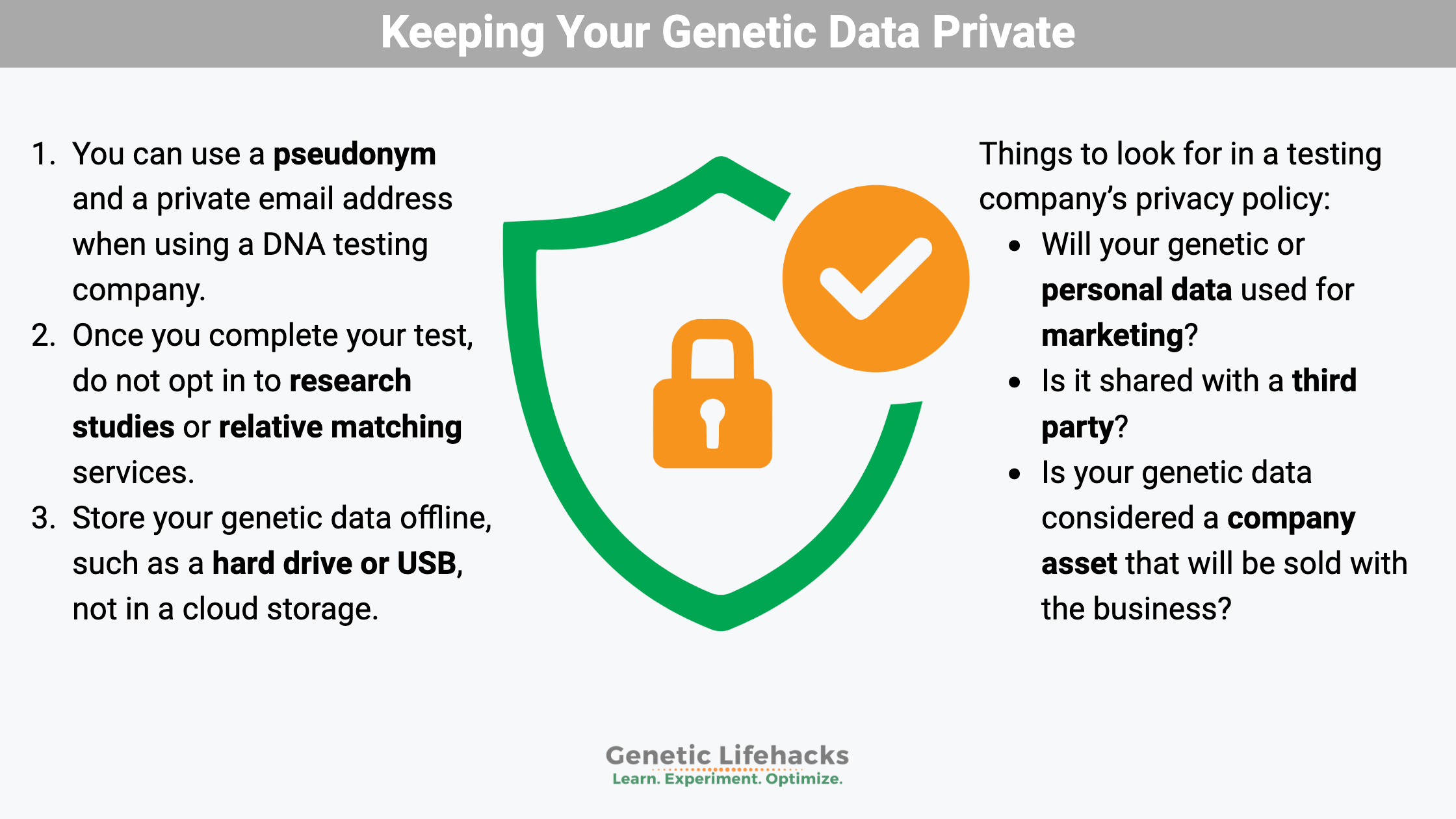
BookmarkDownload this article as a .PDF There is so much you can learn from your genes! I’m a big fan of genetic testing, but I’m also very concerned about the privacy risks of genetic data. Let’s look at some of the concerns about genetic testing and some ways to reduce … Read more

Looking for a deal on 23andMe? If you aren’t in a hurry, wait until it goes on sale. Here are the normal sales dates for 23andMe.

Step-by-step instructions on how to log in to 23 and Me and download your raw data. Be sure to save the file on your computer securely.
BookmarkIt’s easy to get caught up in the hype around a supplement. Perhaps you keep getting emails saying that riboflavin or biotin are the bee’s knees. Or ads on Instagram pushing a brain multivitamin that will give you Einstein-level thinking. I admit it – I love to try a new … Read more

The best way to know if a genetic variant is affecting you is usually to see where you stand with a blood test.

BookmarkAncestryDNA can be a great option for DNA testing. You can download your genetic raw data file and use it on Genetic Lifehacks and other sites. While AncestryDNA generally costs around $99 for the test kit, you can snag a deal for $59 or $69 several times throughout the year. … Read more

Directions on converting a whole genome file into a .txt format that can be used on Genetic Lifehacks.

Quick and easy instructions on how to convert your MyHeritage .csv file into a .txt file. You must use a .txt file to access Genetic Lifehacks membership features.

A quick tutorial on downloading your data from AncestryDNA. If you download it from AncestryDNA, then you can use that data in a variety of ways.

Do you have questions about using your 23 and Me raw data? Check out people’s most common questions about using their 23 and Me gene information.

Do your genes really get ‘dirty’? The quick answer is no but discover the meaning of this concept and how to better relate it to your genes.

Wanting to find out more about genetics or stay current on research? Reddit is one place for discovering new research studies.
You don’t have to order an expensive secretor test if you already have 23andMe, AncestryDNA, or other genetic raw data – just check your genes.

A step-by-step on how to convert the Dante Labs whole-genome file into a format that looks like 23 and Me or AncestryDNA raw data for use on Genetic Lifehacks.

Wondering what MTHFR is all about? Learn what the research says about it and how to check your own raw data file.

An evolving list of Genetic Lifehacks’ favorite health and science-related podcasts for learning from experts in their field.
Wondering whether to go with an Ancestry.com or 23andMe kit? This is a quick, no-nonsense comparison between the two.

This is a quick, step-by-step guide to deleting your DNA data and account on Ancestry.com.

Does the science back up the idea that you can lose weight solely based on your blood type? The article explains the different ABO blood types, breaks down the core ideas of a blood type diet, and offer some food for thought on how to approach these methods. (Member’s article)
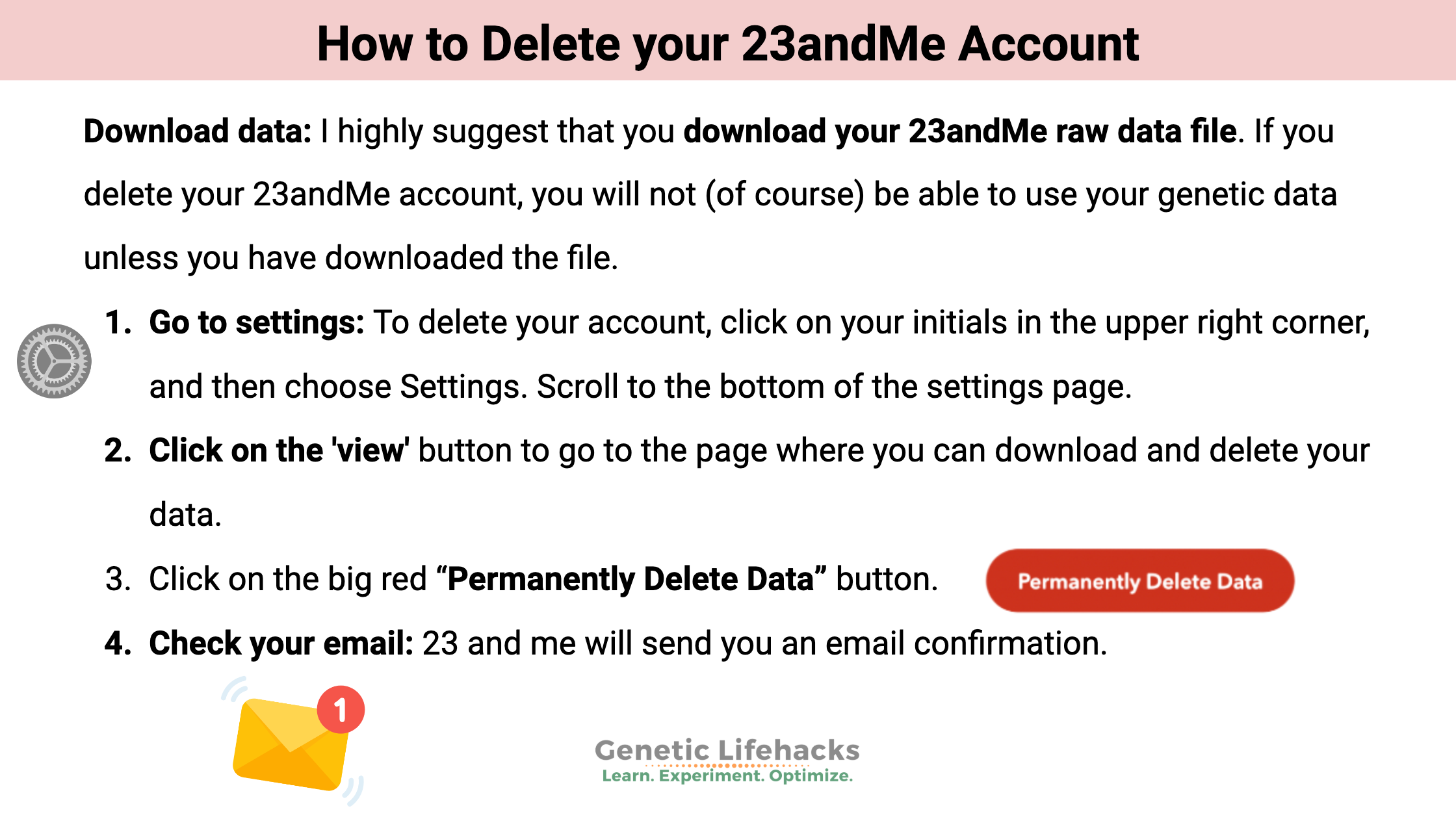
Simple instructions on how to download your data from 23andMe and delete your account.

A look into the newest biological age calculators available. How well do your lifestyle and genetics interact to estimate your cellular age? (Member’s article)
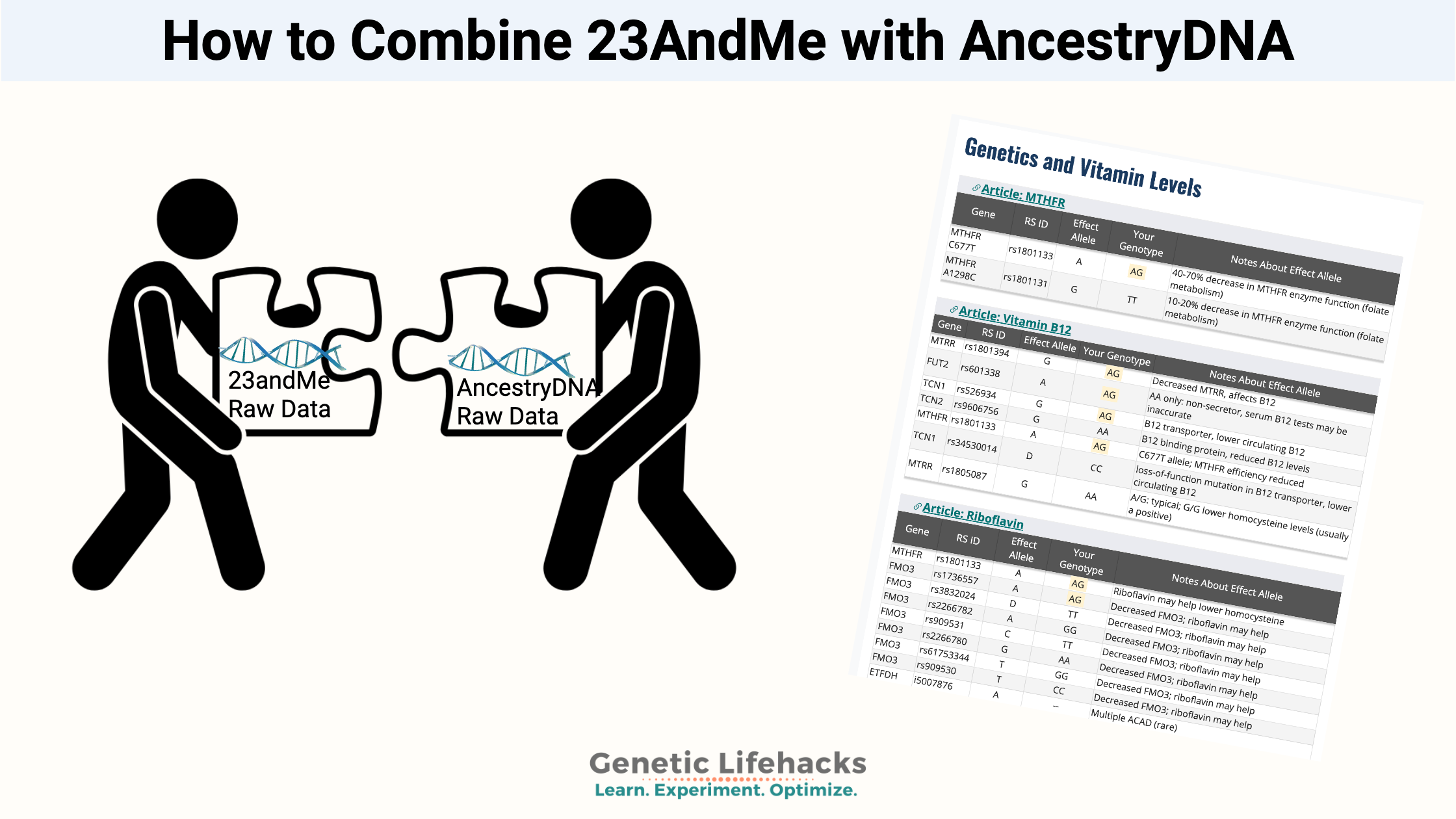
This method of combining the 23andMe and AncestryDNA raw data files involves using a Mac or Linux terminal window. These directions assume you have some minor skills in navigating in a terminal window.
A personal experience review and opinion on the reports offered with Dante Labs’ whole-genome sequencing.